Velociraptor MCP
With the MCP buzz still running hot I thought I would take some time to use and document one that really caught my eye recently.
This MCP, was developed by @mgreen27 and I am very excited to see how it continues to grow.
In this post, I’ll walk through how to spin up a Velociraptor MCP from this GitHub repo, explore what the protocol does under the hood, and demonstrate how you can contribute to or build on it yourself.
Whether you're a threat hunter looking to streamline workflows or a DFIR practitioner building custom tooling, understanding and leveraging MCP will help you take full advantage of Velociraptor’s extensibility.
Personal skippable waffle
I am interested in seeing how the cybersecurity space adapts to MCPs (and AI as a whole..), I believe they should be used in conjunction; i.e - you begin analysing the triage image or acquired artifacts whilst you run a simultaneous query targeting 'known-evil' or anything of the such - this provides us with quick wins and ultimately clues, hopefully reducing analysis time; at no point, at least at the time of writing this do I believe there is a capability for total autonomous analysis. As I recently discussed with SAN's instructor Kathryn Hedley, she stated (rough quote): "It is not that I don't trust my tools, it is just that I must always validate their outputs". GenAI is still in a state of hallucination, and even so you shouldn't switch off your brain and let the tool do all the work for you!
Key things to be aware of before following this doc
1 - A free plan of Claude will not 'completely' work, as you will almost always hit the text output threshold (true for bigger datasets)
2 - You can find the MCP and it's associated README which covers the below at a higher level: https://github.com/mgreen27/mcp-velociraptor
3 - If you are just interested in getting this set up, you can follow up until the How to contribute section where I will discuss how to add additional entries.
The actual content you clicked for
So before our problems are just a prompt away, we must first set everything up!
 |
| Goal example |
Go ahead and clone the mcp-velociraptor repo; I assume you already have Velociraptor downloaded.
So now you should have the following:
 |
| Files example |
Now let's download Claude Desktop
Go ahead and register or login.
Setting up the Velociraptor API
If you haven't yet done so, generate a standard config, this can be done using the following:
velociraptor.exe config generate -i
Here you will need to go through the interactive setup.
I now have my config, MCP Github repo and my velociraptor executable
 |
| Directory example |
Now generate an API token (assuming below it is in the same directory as your Velociraptor executable.
velociraptor.exe --config .\server.config.yaml config api_client --name api --role administrator,api api_client.yaml

API Example
Configuring relevant files
server.config.yaml |
| server.config.yaml |
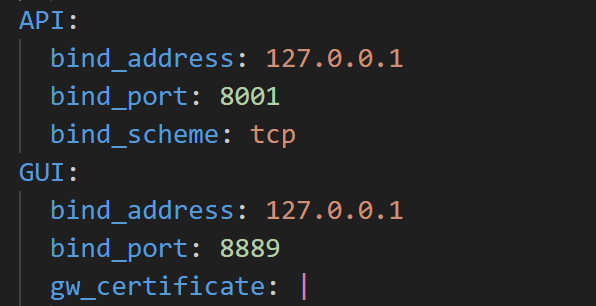 |
| IP:Port example |
api_client.yaml
Here we expect identical IP:port mappings.
 |
| api_client.yaml |
With that out of the way, we can now make some progress.
mcp_velociraptor_bridge.py
Below, you will see the 'api_client_config' variable, we need to point this to ours newly created api_config.
 |
| mcp_velociraptor.py example |
I simply dropped this file into the same directory
 |
| Directory of api_client.yaml |
And expliciltly stated the path C:\.. etc.
Setting up a virtual environment
 |
| Requirements example |
Testing the API
 |
| Velociraptor Splash |
No errors is a good sign, expect something like the following!
 |
| api_test output |
Changing Claude config
 |
| Claude navigation |
Upon clicking 'Edit Config' you will be taken to the config file in question.
Now restart Claude (task manager easy w due to background processes)
 |
| Successful configuration setup |
Using Velociraptor-MCP
 |
| Consent |
And now we have our integration working.
 |
| Output example |
 |
| Output Example |
How to contribute
So as we saw earlier, the bulk of the logic is inside the bridge, if we tear one of these apart per artifact we see quite quickly this is very streamlined and easy to contribute to.
 |
| Core logic block for our purposes |
The author @mgreen27 did state: " have included a function to find artifacts and dynamically create collections but had mixed results. I have been pleasantly surprised with some results and disappointed when running other collections that cause lots of rows.". Thus, additional contributions and work is required - and as you have seen with the above, the capabilities are extremely useful to IR and Threat Hunters.
Case Study
Requirements
- RecentDocs
- Shellbags
*Note: I did not go into adding parameters, which would drastically help reduce data output issues - this is something I hope to cover in a future blog wherein a full analysis of an attack is performed completely utilising this MCP*.
Creating a new entry
First we need to see how this looks in Velociraptor, more so just to get the outputs/fields of interest.
 |
| Artifact example |
Saving, and then restarting Claude gives us access to this information (you will be prompted when a new artifact is used).
 |
| Artifact output example |
After adding in a few of the artifacts mentioned, I got some interesting results.
 |
| The good, the bad and the ugly. |
This is great and the artifacts really helped to bring some analysis and correlation of artifacts together, but it did make some bold statements of this being a sign of exfiltration, when at this point, it did not have any solid evidence that the files hit the USB.
 |
| Questioning |
I intended to go through this whole analysis, but I think this post has already turned into a large block of text and the principles have been covered clearly enough for anyone to setup, test, create and continue testing and finally utilising.
After confirming it works, we should look to add to the project as a whole, which can be done via Github.
Features I didn't cover
 |
| Failed query due to size resulted in another artifact being queried. |
The above displays the capability to collect artifacts outside of the pre-defined list, which I observed numerous times and was stated by the author himself.


Comments
Post a Comment